BEng Thesis: PPO vs Robust MPC on a Simulated Roomba
Controller benchmark in simulation: trajectory tracking, obstacle avoidance, and robustness under noise and disturbances.
BEng thesis — Warsaw University of Technology, Nov 2025. Supervisor: Prof. Marcin Żugaj, DSc, Eng. Source: Chapters 5–6.
What this thesis is about
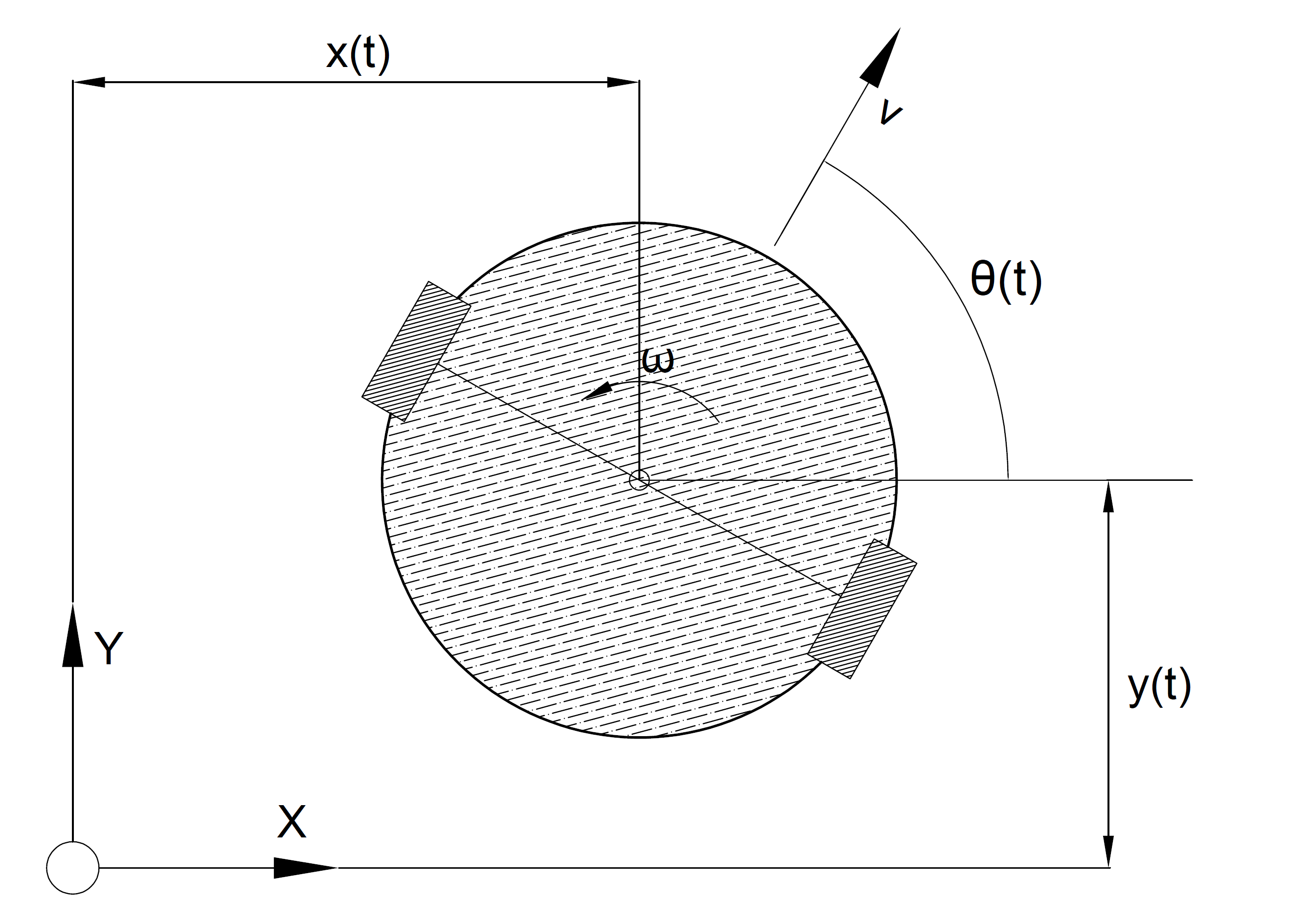
A simulated ground robot navigates cluttered indoor environments, following a reference path to a goal while avoiding obstacles. The thesis asks one question: when GPS positioning is jammed mid-run, which controller holds up better — Tube Robust MPC, with formal safety guarantees, or PPO, a neural network trained through reinforcement learning? Both were benchmarked head-to-head across 500 identical environments under nominal GPS and GNSS-denied conditions.
Controllers at a glance
- Predicts future states using an explicit dynamics model
- Tube formulation bounds the effect of noise — hard constraints guaranteed
- Conservative by design; higher online compute cost
- Policy learned through simulated trial-and-error — no explicit model
- Single neural-network forward pass; 63× faster online than RMPC
- No formal stability or obstacle-avoidance guarantees
In action — GNSS-denied run, environment 044
Same environment, same conditions. Watch how each controller handles the denial zone.
Experiment at a glance
RMPC recorded zero collisions in both nominal and GNSS-denied conditions. PPO collided in 3.1% of nominal runs and 4.7% under GPS denial — a direct result of operating without hard obstacle-avoidance constraints.
Results Visualised
Success Rate
Cross-Track Error — lower is better
Raw Results (Thesis Table, N = 500)
| Metric | RMPC (nominal) | PPO (nominal) | RMPC (denial) | PPO (denial) |
|---|---|---|---|---|
| Success [%] | 89.8 | 93.6 | 85.2 | 91.3 |
| Collision [%] | 0.0 | 3.1 | 0.0 | 4.7 |
| Timeout [%] | 10.2 | 3.3 | 14.8 | 4.0 |
| XTE_nom / XTE_mean [m] | 0.2664 | 0.7312 | 0.3245 | 0.8515 |
| XTE_in [m] | -- | -- | 0.3209 | 0.2099 |
| XTE_out [m] | -- | -- | 0.3276 | 0.8667 |
GNSS Denial: Performance Impact
P_deg-nom compares tracking error under denial vs. nominal. P_deg-InOut isolates whether degradation occurs inside the denial zone or outside it. RMPC's −0.95% means it degrades uniformly throughout. PPO's −75.8% reveals it tracks well inside the denial zone but accumulates large error once outside — suggesting position drift that compounds after denial ends.
Study Setup
- Controllers: Tube RMPC and PPO.
- Evaluation dataset size: N = 500 environments.
- Same worlds used for both controllers and both denial configurations.
- Conditions: nominal and GNSS-denied operation.
Key Metric Definition
Tracking quality is measured with Cross-Track Error (XTE), defined as the Euclidean distance from robot position to the nearest reference waypoint with monotonic index progression along the path.
Cost of Deployment
Rollout speed measures how fast each controller issues actions during operation. PPO's advantage (63× faster) comes from a single neural-network forward pass, versus RMPC solving an online optimisation problem at each timestep.
| Metric | Tube RMPC | PPO |
|---|---|---|
| Implementation time [man-hours] | 24 | 120 |
| Training/tuning duration [h] | 2 | 250 |
| Rollout speed [actions/s] | 20.2 | 1270 |
Verdict
RMPC is the clear winner where hard constraints matter. Zero collisions across 1 000 runs, predictable degradation under denial, and formal guarantees on obstacle avoidance make it the right choice for safety-critical applications — at the cost of slower online execution and a more complex implementation.
PPO matched or exceeded RMPC on raw success rate and runs 63× faster online. Its policy adapts naturally without an explicit model — but the 3–5% collision rate and lack of formal guarantees disqualify it from safety-critical use as-is.
No universal winner. RMPC is the right choice when safety is non-negotiable; PPO when throughput and adaptability matter more than constraint guarantees. The real value of this thesis is the direct, controlled comparison under identical conditions — a practical baseline for future controller design decisions.